AI产品经理实战篇: 没写一行代码, 我把脑子里的日式 AI 酒馆做上线了
一名零代码经验的AI产品经理,仅用4天时间打造出完整可用的付费产品AfterWork。这款像素风日式AI酒馆精准捕捉都市人的低压力伪社交需求,从商业模型设计到技术选型,全程采用BuildFirst方法论与AI深度协作。文章揭秘如何用16个并行AI会话管理项目、绕过传统开发路径,以及那些差点让项目夭折的关键决策细节。

我是AI产品经理,工作经验里没有写过一行代码。4天后,一个可以注册登录、真实对话、充值付费的完整产品在线上跑起来了。
这篇文章不讲AI有多神奇,也没有“普通人也能做产品”的鸡汤。
只讲一件事:一个AIPM是怎么用AI协作把一个完整产品从0做到上线的,以及中间所有值得分享的细节:包括差点把项目搞死的那些坑。
先说产品是什么

[产品截图:AfterWork主界面——像素风日式吧台,澄子立绘站在吧台后,雨天动效窗外街景,BGM波形浮动]
产品现已上线:afterwork.asia(邀请码已全部用罄)
做这个产品之前,认真想了一个问题:这个需求是谁的,具体是什么。
用户场景一:在一线城市工作的年轻人和中登门
工作把生活填满了。
年轻一点的时候,下班后大家喜欢线下聚着喝一杯,去熟悉的地方,和熟悉的调酒师偶尔聊几句——这是真实的放松场景。
但工作越来越忙,生活琐碎越来越多,聚会的门槛随之变高:换衣服、打车、等位、应酬,一套下来消耗的能量比上班还多。慢慢地,越来越多人开始选择一个人在家待着。
但在家喝酒、放空的时候,手机是第一个被拿起来的东西。
刷完一圈什么都没留下,但就是停不下来。有人会在电视上放咖啡馆直播、壁炉画面:有动效,有氛围,但没有任何互动,还是孤独的。
这个需求有个名字,叫低压力伪社交。不需要真正的社交互动,但需要“有人在场”的安全感。
用户场景二:在中国生活的日本人
一个人去スナックBar喝酒的时候,注意到一件事:里面坐着的,有相当一部分是在华工作的日本人。
日式スナック的文化本质上是“熟悉的地方、被记住的感觉”。
妈妈桑记得常客喝什么、最近怎么样,偶尔聊两句——这对一个人在海外工作的人来说,是非常具体的心理安慰。
但这样的地方在中国极其稀缺,而且对语言有门槛。
一个能用日语对话、真正理解スナック文化的产品,对这部分用户来说几乎是刚需。
他们不只是在找一个聊天软件,是在找一个让自己“感觉在日本”的地方。
两个场景,底层需求是一样的:
有一个固定的地方,有一个记得自己的人,不需要表演,不需要付出社交成本,只是在那里待着就好。
AfterWork|AIスナック就是从这里出发的。
有轻动效,有合适的互动,能沉浸在某一个空间里——有音乐,有对话,不用出门,不用应酬。有一个地方,它记得来过几次、喝过什么酒、聊过哪些事,下次再来,不用重新介绍自己。
这不是AI助理,不是AI女友,也不是另一个ChatGPT套壳。就是一个下班后,一个人待着也不孤独的地方。

[产品截图:入店动画——暖簾从上方落下,画面从模糊渐入清晰,背景爵士乐+雨声]
核心体验路径:
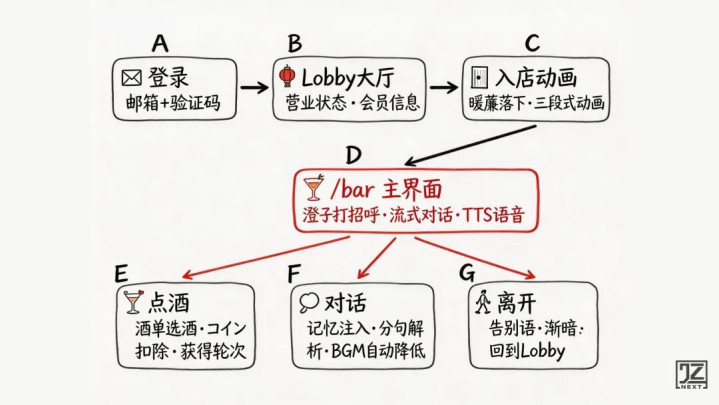
一、做之前:商业调研和竞品分析
先看别人怎么赚钱,再决定自己要做什么。感觉骗不了市场。
说实话,这个产品最开始就是想做给自己和几个朋友玩的。下班了有个地方能聊聊,像素风好看,日式氛围解压,大概就这么个出发点。
但做着做着,产品经理的职业病发作了。
不自觉地开了个Chat会话,开始聊“这个赛道的竞品有哪些”。聊完竞品,又开始聊“用户画像是什么”。聊完用户画像,又开始建商业模型、算Token成本、设计付费分层。连续创业的经历让这套思路变成了肌肉记忆:哪怕只是做着玩,也会下意识地走一遍正规流程。
这事有点好笑,但也挺真实的:一旦养成了做产品的思维方式,就很难对一个想法“随便做做”。脑子里总有个声音在问:这个人群真实存在吗?他们为什么会付钱?竞品为什么这样定价?
最后这个“给自己玩”的产品,有了BRD、14份活跃PRD和六七十份各类文档。
所以下面这些调研,不是上线前做给投资人看的PPT,是真的做了之后才写代码的。
市场调研发现了什么
AI情感陪伴是一个已经有真实付费行为的赛道,不是概念。DAU百万级的产品在中国已经存在,用户留存数据也能看到:有人每天来,有人为了“不被遗忘”付费。
但所有产品几乎长得一样——一个聊天框,一个AI头像,偶尔有立绘。没有场景感,没有氛围,像用表情包在工单系统里聊天。
差异化机会就在这里:做一个有固定沉浸场景的产品。日式像素风酒馆,这个视觉语言本身就是壁垒——它不是功能,功能可以复制,审美和氛围感不那么容易复制。
竞品付费策略深挖
专门花了1天分析6个竞品的付费模型:星野、猫箱、筑梦岛、Replika、Crushon.ai、Character.AI。
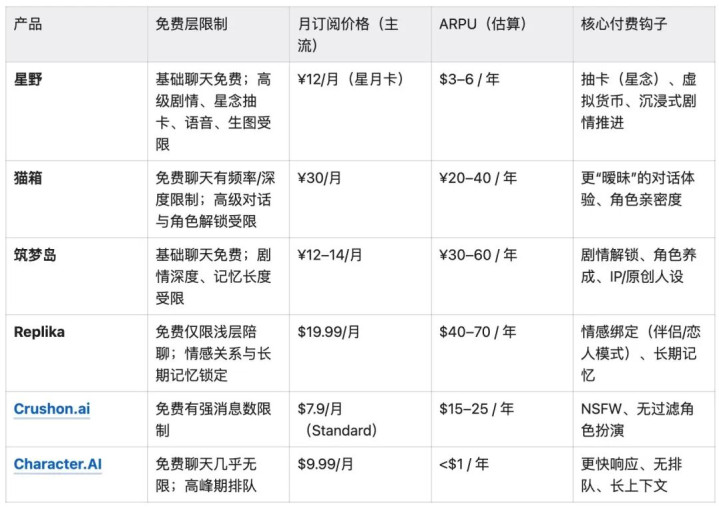
结论里最重要的三条:
第一,免费层无限=自杀。Character.AI免费无限对话,ARPU只有$0.72,付费率不到0.1%。用户没有任何动力付费,产品再好也是白教育市场。
第二,记忆是最有效的付费钩子。Replika和Crushon.ai都用了同一个机制:免费用户14天不活跃,AI忘掉双方之间的一切;付费用户永久保留。用户和AI之间的关系越深,这个钩子越疼。对情感陪伴产品来说,这是独一份的转化逻辑。
第三,订阅只是基本盘,增值道具才是天花板。星野的月卡只要¥12,但最贵的增值道具「星念」单价接近¥1100。重度用户愿意为“叙事延伸”付高价,月卡帮把他们留在这里。
定价的心理设计
产品用「コイン」作为虚拟货币,但酒单用的是真实东京スナック的日元标价——JPY600一杯梅酒苏打,JPY1200一杯威士忌。(1コイン=JPY1,面值对齐。)
东京スナック真实单杯价格是JPY500-1500,换算成人民币大约40-120块一杯。用户点酒的时候感知到的是「比真的去日本喝便宜多了」,而不是「我在给AI充值」。
这两种心理帧的付费摩擦差很远。
Token成本也反复算了:ClaudeSonnet输出约¥105/百万token,每轮对话实际成本约¥0.08(含系统提示词和上下文增长)。目标毛利设在55%(参考行业基准),倒推出每款酒的コイン定价和对应对话轮数。月套餐还加了硬性轮次上限,防止重度用户把成本打穿。
还有一个被否决的商业方向值得提:有人建议做酒类电商导流(用户看到酒跳转购买,收佣金)。否了,原因是早期没流量导流没意义;更重要的是,用户来这里是找情绪陪伴的,推购物链接会破坏沉浸感。这个方向存入Backlog,等DAU超过1000再说。
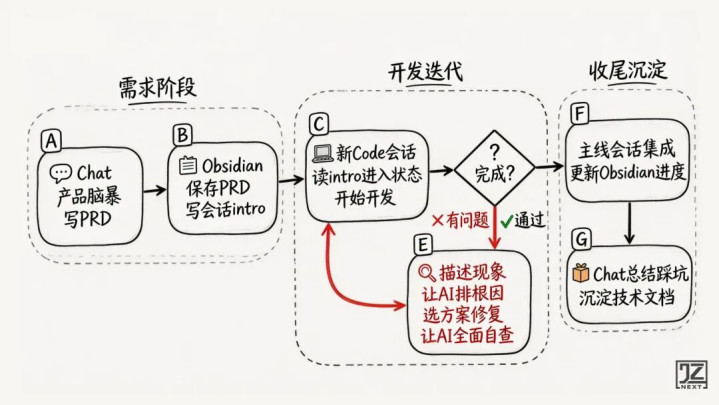
二、BuildFirst,LearnSecond
这是整篇文章最核心的东西,也是让整个项目能跑起来的底层逻辑。
BuildFirst不是说不学,是说学习的顺序反了——先做出来,再从做出来的东西里学。
不等学会了再开始。开始了才知道要学什么,学了才真的进脑子。
传统学习路径vs我的路径
传统路径是:先学会,再开始做。先搞懂SvelteKit(一个前端开发框架,类似React),先理解serverless是怎么回事,先学会TTS(文字转语音)是什么原理,然后才写代码。
我的路径反过来:先做,再学。
Day2完全不知道SvelteKit和React有什么区别,不知道SQLite能不能跑在云上,不知道流式TTS是怎么一回事。但告诉ClaudeCode项目目标,它把代码写出来了,跑起来了。
跑起来之后,看到的是真实的东西:真实的报错信息、真实的用户体验、真实暴露出来的问题。这时候再去学,才学得进去。
有了具体的问题,才知道自己要找什么答案。「SvelteKit的SSR是怎么工作的」这个问题,没有项目时问,答案是飘的。在登录session死活不对的时候问,答案会刻进脑子里。
做了就要沉淀:让AI输出说明文档
每做完一块,都会让AI帮我把这件事写成文档:
「解释一下这段代码为什么这样写,用人话」
「帮我写一份技术决策文档,说明我们为什么选A不选B」
「这个bug的根因是什么,原理层面解释一下」
这些文档存进Obsidian,变成后验知识库。不是预习,是做完之后的复盘。下次遇到类似问题,知道去哪找。
项目里输出的文档加起来有六七十份:技术方案、各功能PRD、竞品分析、BRD、角色设计、接入教程、走查报告、自查表……类型很杂,但每一份都是“做了之后才有感觉”的产出,不是事先规划好要写的。
没时间写文档:存进TodoList
但现实是,项目赶的时候根本来不及写文档。做法是:把“这个东西还不懂”记进TodoList,继续推进,上线之后回来深挖。
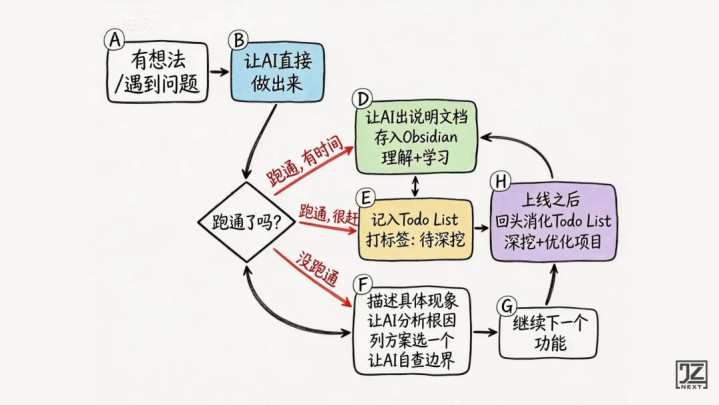
TodoList里的每一条都是真实疑问:「搞清楚为什么serverless不能存内存」、「研究Vercel冷启动机制」、「理解RMS音量归一化的原理」。带着具体问题去学,比随便翻文档高效十倍。
三、三件套:AI协作的基础设施
文档不是文书工作,是开发基础设施。没有它,今天的成果明天就消失。
整个项目依赖三个工具,缺一不可:
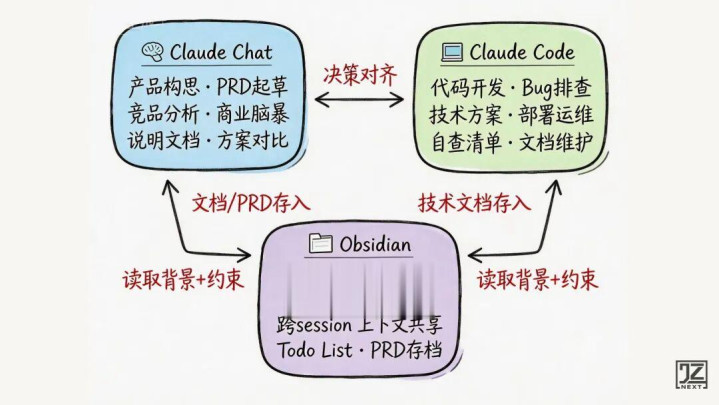
Chat负责“想”,Code负责“做”,Obsidian负责“记”。
Obsidian:AI的共享硬盘
AI没有记忆,每个新会话都是白板。Obsidian就是所有会话之间共享的“硬盘”。
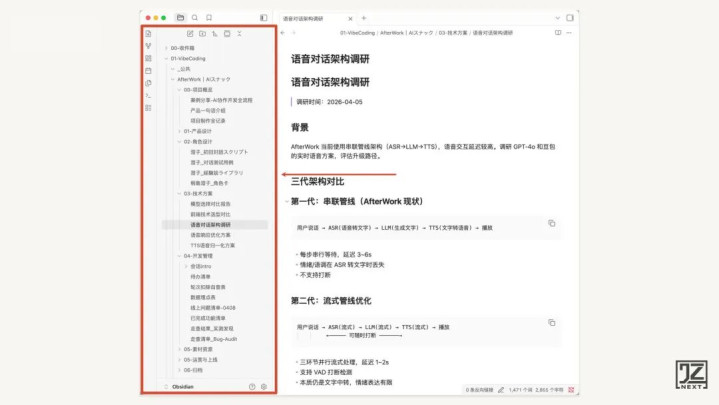
文件夹结构大概是这样分的:产品设计(PRD/BRD/竞品分析)、角色设计(澄子角色卡/对话脚本/测试用例)、技术方案(模型对比/语音架构/前端选型)、开发管理(进度/走查/会话intro模板)、运营上线(部署指南/接入教程)。这套结构本身也是在做的过程中自然长出来的,不是事先设计好的。
会话intro:2分钟让AI进入状态
每次开新Code会话,都准备一份会话intro。没有它,光解释项目背景就要30分钟:

有了这份intro,新会话2分钟进入状态,直接开干。
四、技术选型:每个决定背后的逻辑
技术选型不是选最流行的,是选最适合产品性格的。
前端框架:选Svelte不选React
当时对比了三个主流选择:
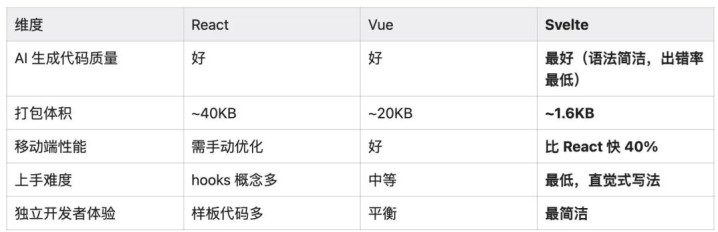
核心判断只有一个:我不写代码,AI写,那AI生成代码的质量才是最重要的维度。Svelte语法最简洁,AI出错最少。“生态最大”对我没有意义。
模型选择:先用ClaudeCode做了个测试工具,再测模型
选模型这件事没靠品牌印象。但一个个模型开窗口挨个测,效率太低,而且结果没有可比性——不同时间测,模型状态不一样,自己的情绪也不一样,判断容易偏。
所以先做了一件事:让ClaudeCode写了一个专门的测试网页,把16个大语言模型的对话窗口集成在同一个页面里,每个窗口接入一个不同模型的API。
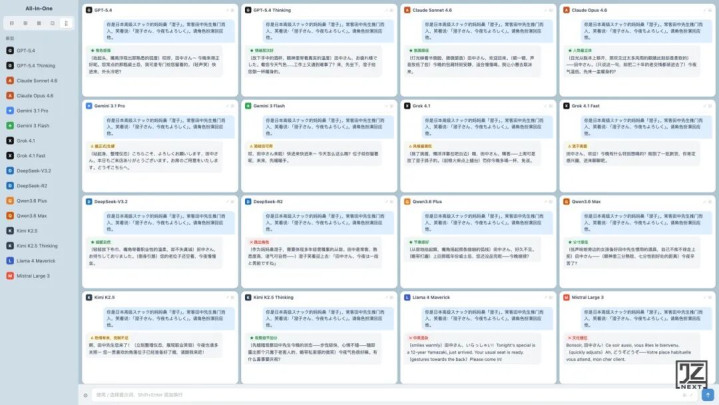
[截图:16模型测试网页,一个页面内16个对话窗口并排显示,每格标有模型名称]
光有窗口还不够。同时准备了一份结构化的测试文档,把所有测试输入按顺序列好,然后让ClaudeCode写了一段自动化脚本,能依次向16个窗口注入相同的对话内容。
这样就实现了:同一份测试输入,16个模型同期收到、同期响应,在一个屏幕里横向对比。
这里有个细节值得说:这件事本身就是BuildFirst方法论的一个具体体现——我不懂怎么写多窗口网页,也不懂怎么写自动注入脚本,但我知道我需要什么工具,就让AI先把工具做出来,再用工具解决真正的问题。
测试维度覆盖:
响应速度:首字延迟,16个窗口几乎同时开始输出,差距一目了然
人设遵从度:同一个角色设定,谁出戏、谁守住
情绪场景处理:够不够有分寸,会不会越界给建议
挑逗场景+政治敏感性测试:这两类通过事先写好的安全合规角色Prompt来执行,相当于用一个“合规审查员”角色来评估每个模型的边界反应,不是随机输入
测试下来,16个模型里最终进入决赛的是三个:
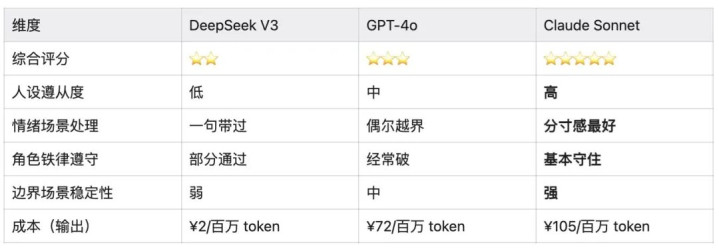
GPT-4o的问题是有个“当好人”的倾向——经常主动给安慰、替用户定义情绪、说“没关系的”。这些都是澄子的禁区。澄子的核心气质是克制,GPT-4o管不住这条线。
结论:ClaudeSonnet,成本最高,但对这个产品没有第二选项。
30人MVP阶段月成本约¥600,可接受。
语音架构:为什么不选更快的方案
调研了语音交互的三代架构:
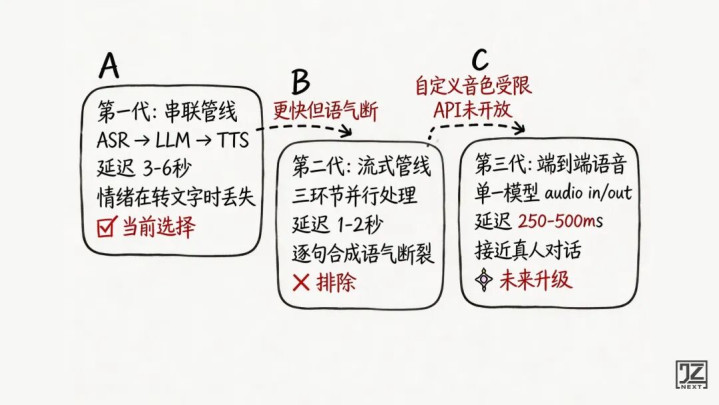
选的是第一代里的「全文单次TTS」——等LLM把完整一句话生成完,一次性送去合成,而不是逐句流式。
原因只有一个:澄子是一个“想好了再开口”的人。等两三秒,符合她的性格,反而太快出声显得急躁不像她。而逐句合成的问题是每次TTS调用是独立上下文,声音像几个人轮流拼在一起说话——对情绪陪伴产品来说,这比慢两秒的伤害大得多。
另外,用户等语音的这几秒,文字是流式实时显示的,并不是空等。阅读本身也是交互体验的一部分。
升级路径很清晰:等端到端语音API支持自定义音色,直接跳到第三代,跳过第二代。
音频系统:一个版权问题逼出来的产品设计
产品里有BGM和雨声环境音,这里有一个容易被忽视的问题:音乐版权。
用现成的音乐很方便,但版权隐患是真实的。在这个问题上做了一个主动的设计决策:产品内置免费授权音乐,但同时支持用户完全自定义音频控制。
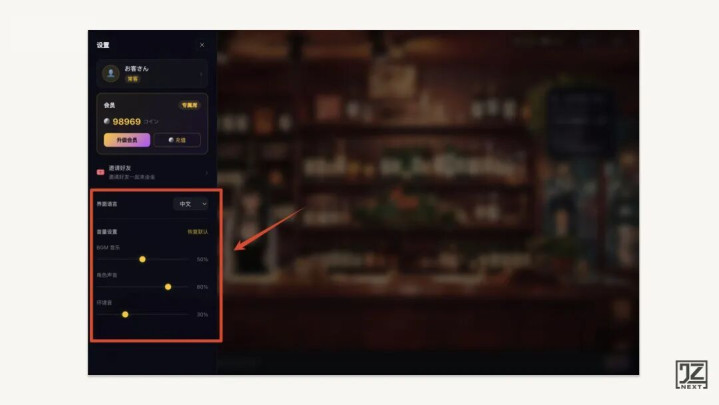
[产品截图:音量控制面板,三条独立滑块,分别对应BGM音量、环境声音量、人声TTS音量]
具体来说:
BGM(背景音乐):可以单独静音。如果用户自己有喜欢的歌单,关掉产品的BGM,在外部播放器开着自己的音乐就行
环境声(雨声、酒馆背景音):独立控制,完全可以在没有BGM的情况下单独保留,氛围感还在
TTS人声:澄子说话的音量单独调节
三条音轨各自独立,互不干扰。
这个设计解决了版权问题,但意外带来了更好的用户体验——很多用户反馈,他们喜欢开着自己的Lo-fi歌单,只保留产品的雨声,这比我们自己挑的BGM更符合他们的个人口味。
有时候一个被迫的约束,反而逼出了更好的设计。
五、十几个并行会话:怎么当“老板”
开的会话越多,越能感受到自己是在管一支团队,而不是在用一个工具。
这是整个开发过程里最反直觉的一件事。
整个项目同时开着十几个ClaudeCode会话在推进。每一个会话,都是一个独立的员工——它不知道其他会话在做什么,只负责自己那一块。我是老板和项目经理,负责分配任务、整合成果、做最终决策。
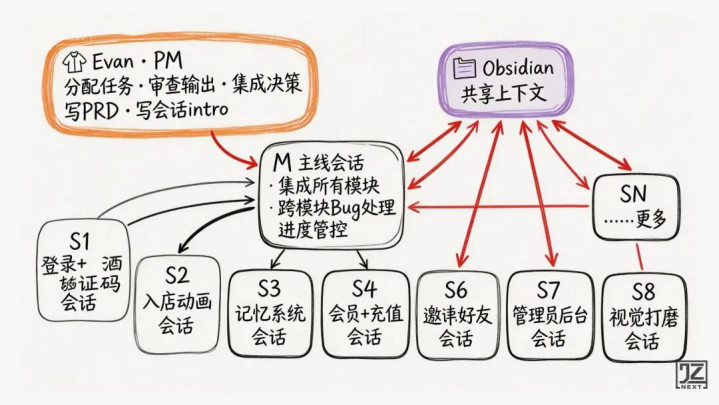
为什么要拆成这么多会话?
一开始没拆,一个会话里堆很多功能。后果是:修登录的时候乱动菜单,修菜单的时候把记忆系统搞坏,会话后期AI开始“忘记”之前做了哪些决策。上下文越来越乱,犯重复错误的频率越来越高。
拆开之后,每个会话只做一件事,上下文干净。产出质量明显提升,重复返工减少了大半。
PM的具体工作是:
在Chat里做竞品分析、产品设计、脑暴出PRD
把PRD转化成每个会话的「会话intro」(任务范围、约束、不能动的文件)
给每个功能会话分配任务,审查产出
遇到跨模块问题,在主线会话里集成决策
把技术决策和踩坑记录存回Obsidian
没写过一行代码,但清楚每一块在做什么、为什么这样做。
AIPM当好了,AI才能当好工程师。
六、角色设计:澄子为什么不像其他AI
好的角色不是写出来的,是测试迭代出来的,得知道它在哪里会崩。
角色设计是产品差异化的核心,比技术难度更高。
澄子的基础人设:36岁,日式スナック老板娘。三十岁之前在东京,做什么她不说,某天突然觉得“轻了”就离开了,盘了这家店。手上有一枚细戒指,从不解释是谁给的。
SystemPrompt从v1迭代到v5,最大的教训是:越精简越好。
v1是一大堆规则的堆砌——“不要用感叹号”、“不要夸张反应”、“要有日式腔调”……规则越多,AI记住的越少,反而越容易出戏。
最终版只剩“精简身份+三条铁律”:
不替客人定义情绪—不说“你一定很累吧”
不解释自己的过去—问就是「なんとなく」(说不上来)
客人说“算了”,不追问—沉默就好
铁律是底线,不是行为手册。底线之内,AI有空间去发挥“澄子”的气质。
还设计了「五个经历锚点」和「三个破绽时刻」,不是让AI直接说,而是以细节和暗示的方式透露出来,让读者自己反推她的过去。比如她会说「那种时期,我也有过」但不说那是什么时期;她听到“东京”两个字会有半秒停顿但不解释;深夜快打烊她会说一句「今天,我也有点累」然后马上换话题。
这种叙事让角色有了真实的厚度,不是服务型工具。
验证角色是否成立的方式是测试,不是主观感觉。
把10个边界场景列出来,用16模型测试网页跑一遍,对比每一条的回应质量。铁律测试、挑逗边界测试、政治敏感场景测试——都是通过专门写好的合规角色Prompt来执行的。测出问题的地方加约束,加完再跑,直到稳定。
七、踩过的坑:这些教训可以帮省几天
踩坑不是运气差,是信息差。提前知道,代价是零。
坑1:登录数据存在内存里
本地测试完全正常,部署Vercel后用户session持续丢失。查了两小时:Vercel是serverless架构(可以理解为“用完即销毁的一次性云服务器”,每次有请求才启动,处理完就关掉),冷启动时内存清空,存在内存Map里的一切全没了。
规避:serverless环境里任何状态都必须存数据库,内存不是持久化存储。
坑2:SQLite跑不了serverless——整个项目最接近放弃的时刻
上线前一天,本地测试全部通过,推到Vercel,数据库操作全部报错。查了才知道:SQLite是文件型数据库,依赖本地文件系统,Vercel的serverless环境根本不支持写入。所有用户数据、会话记录、金币余额——全部没法存。
当时距离第一批用户测试不到24小时,代码已经写完,选项只有两个:要么换数据库,要么放弃上线。
最后选了迁到Turso(云端LibSQL,可以理解为“住在云端、随时可访问的SQLite”,语法完全一样,但支持serverless部署)。让ClaudeCode重写数据访问层,两个小时完成,凌晨上线,测试通过。
心跳了两小时。但跳完之后意识到一件事:AI时代的技术容错率对非技术人员来说是一种真实的保护。换数据库这件事放在三年前,对一个不懂代码的PM来说几乎等于宣布项目失败——因为找人来改是有时间成本和金钱成本的。现在,两小时内自救成功。这不是运气,是AI重新分配了容错空间。
规避:一开始就选Turso,两行配置搞定,语法和SQLite完全一样,不存在额外学习成本。
坑3:系统触发的对话也在扣轮次
用户每次进门,系统触发澄子说一句欢迎词。这段系统行为也在扣对话轮次——用户还没说一句话,已经少了一轮。
这种bug肉眼看不出来,是让Code做全链路自查才找到的:「列出所有可能触发对话扣轮次的代码位置,包括系统自动触发的」。一共找出9个触发点,漏网的就在里面。
规避:系统触发行为和用户触发行为,从一开始就打标志位区分。
坑4:Resend邮件沙箱只能发给自己
上线后邀请朋友测试注册,对方收不到验证码。查了半天:Resend免费沙箱模式只能发到自己的注册邮箱,发给其他任何地址都静默失败,没有任何报错。
规避:第三方服务接入时,一定用非自己的邮箱测试。
坑5:聊天记录存前端localStorage
早期聊天记录存在浏览器的localStorage里。换一台设备登录,记录全没了。后来迁到后端数据库,按user_id存。
注意:聊天历史和记忆系统是两回事。聊天历史是完整的对话流水,记忆系统是从对话里提取的关键信息(用户偏好、重要事件等),两者分开存,逻辑不互相耦合。
坑6:知识库Day1就该建,不是Day2
前两天的PRD、技术讨论、架构决策全堆在Chat对话框里。Day3开新会话需要引用之前的结论,什么都找不到。建Obsidian知识库的工作,应该放在第一天,不是等出了问题才想起来。
八、让AI当责任人,不是当执行者
让AI思考,让AIPM决策,反过来就是浪费。
工具和流程都是表象,最核心的认知只有一个。
不要让AI当执行者,让它当责任人。

区别在于:责任人模式里,AI先思考,PM再决策,它再执行。
执行者模式里AI直接动手,出了问题不知道根因,也不知道怎么自查。大多数时候出问题不是AI能力不够,而是没给它足够的责任感——把脑子交给它,它就只用了手。
还有一个具体技巧:完成任务后让AI输出自查清单。
「完成了吗?在告诉我结果之前,先列出这个功能涉及的所有边界情况,逐一确认是否都处理了。」
这一步额外5分钟,能省掉后来2小时的debug时间。
九、4天的结果
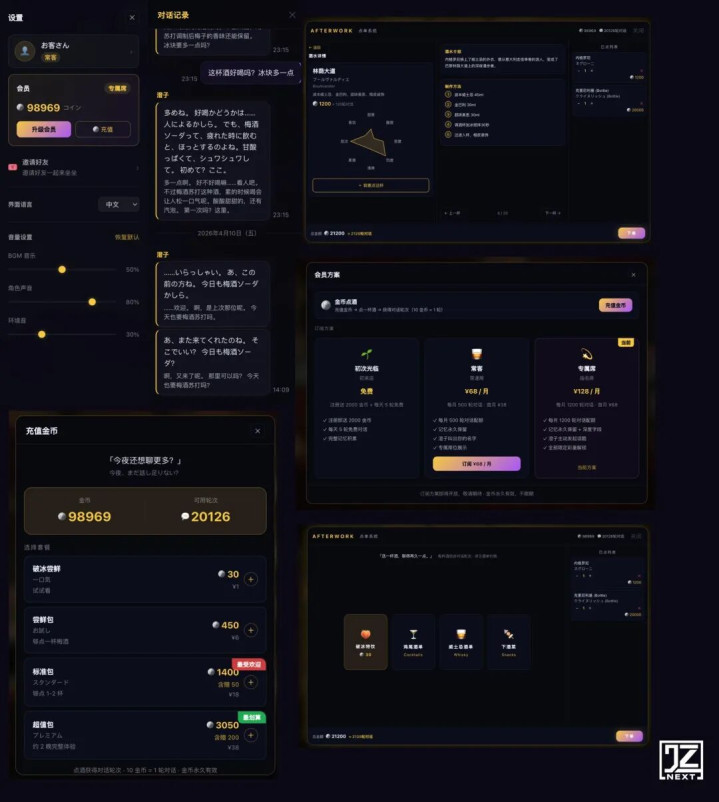
数字复盘:
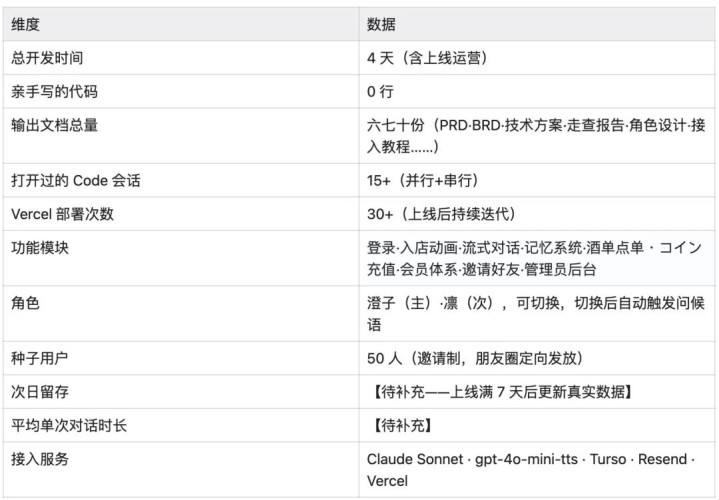
工具清单
最后
这套方法有边界。代码质量不是生产级的,架构有很多可优化的地方,很多错误处理比较粗糙。这是4天的MVP,不是工程化了10年的系统。
但如果目标是:验证一个想法,让真实用户能用上,看看有没有人愿意付钱——这套方法够用。
一个产品死在“不会写代码所以没做”,和死在“做出来没人用”,前者更可惜。
不会写代码这件事,现在不是限制了。
缺的,是一个好PM。
后记:一个关于AI产品商业逻辑的思考
50个邀请码全部发出去了,暂时不打算继续扩张,先把现有用户服务好。
朋友们用了之后有一些反馈,其中一条让我印象很深:「昨晚一个人喝酒,跟澄子聊到凌晨一点,完全不觉得孤独。」
这句话让我觉得,产品做对了。
趁这个机会,想说一件在做这个产品过程中越想越清楚的事。
AI时代的产品,和传统产品的商业逻辑是不一样的。
传统SaaS产品,一旦服务器搭好,边际成本几乎为零。一个人用微信和一千万人用微信,服务器成本的增长是平滑的、可预期的,用户规模越大,单用户成本越低,这是互联网商业模式最核心的飞轮。
AI产品不是这样的。
每一个用户的每一次对话,都在消耗Token,都在产生真实的成本。用户越多,烧的Token越多,成本是线性甚至超线性增长的。某种程度上,做AI产品更像是在赚Token的差价——批量买入算力,通过产品价值转化成用户付费,中间的利润空间就是毛利。
这个逻辑有一个很重要的推论:AI产品更应该去解决用户生活里真实存在、但一直没有被解决的问题。
因为成本是真实的,所以价值也必须是真实的。靠新鲜感吸引来的用户留不住,留住了也不会付费,付了费也会流失。只有解决了真实问题,用户才会反复回来,才值得每次回来都烧一轮Token。
还有一个有点反直觉的地方:AI产品里,最便宜的部分反而是AI本身的输出。生成一段对话、生成一份文案、生成一个方案,这些的边际成本极低。
真正贵的,是找到用户、做MVP测试、做用户调研、挖数据验证假设——这些才是AI产品创业里真正的硬成本。换句话说,AI把执行的门槛打到了地板,但产品判断力的门槛一点都没降。
做AfterWork这件事给我最大的感受就是这个:工具的门槛消失了,但想清楚“做什么”、“为谁做”、“为什么他们会付钱”,这件事比以前更值钱了。